2.6 MESSAGE CONSTRUCTION RULES
This section addresses HL7 general rules for composing messages. Both the sender and receiver of the data must have predictable rules for how they will process the data. The reader is also referred to Section 2.B, "Conformance Using Message Profiles", where procedures for ensuring messaging integrity are discussed in detail.
In constructing a message, certain special characters are used. They are the segment terminator, the field separator, the component separator, subcomponent separator, repetition separator, escape character and the truncation character. The segment terminator is always a carriage return (in ASCII, a hex 0D). The other delimiters are defined in the MSH segment, with the field delimiter in the 4th character position, and the other delimiters occurring as in the field called Encoding Characters, which is the first field after the segment ID. The delimiter values used in the MSH segment are the delimiter values used throughout the entire message. In the absence of other considerations, HL7 recommends the suggested values found in Figure 2-1 delimiter values.
Note: These message construction rules define the standard HL7 encoding rules, creating variable length delimited messages. Although only one set of encoding rules has been defined as a standard since HL7 Version 2.3, other encoding rules are possible (but since they are non-standard, they may only be used by a site-specific agreement).
2.6.1 Rules for the sender
2.6.1.0 Message Construction Pseudocode
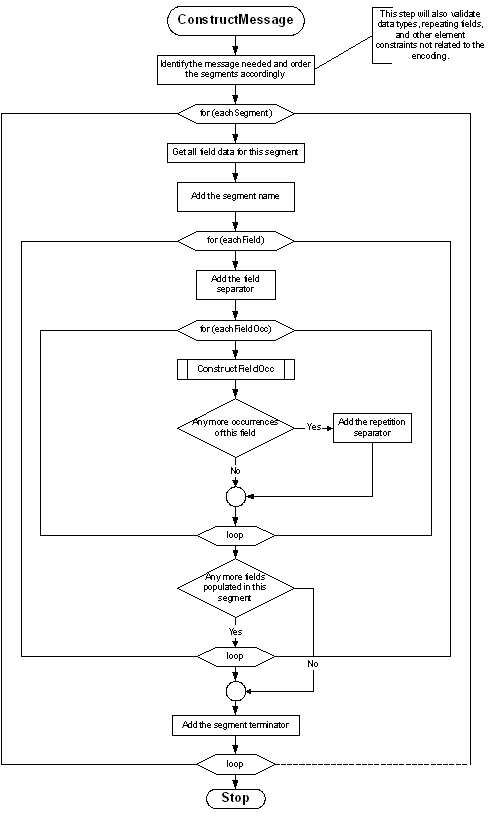
procedure construct_message ( data ) {
identify_message_needed;
identify_separators_used;
validate( data );
order_segments( data, segment_list );
foreach segment in ( segment_list ) {
insert segment.name; /* e.g., MSH */
/* gather all data for fields */
foreach field in ( fields_of( segment ) ) {
insert field separator; /* e.g., | */
/* gather occurrences (may be multiple only for fields that are allowed to repeat */
foreach occurrence in ( occurrences_of( field ) ) {
construct_occurrence( occurrence );
if not last ( populated occurrence ) insert repetition_separator; /* e.g., ~ */
}
break if last ( populated field );
}
insert segment_terminator; /* always<cr>! */
}
return;
}
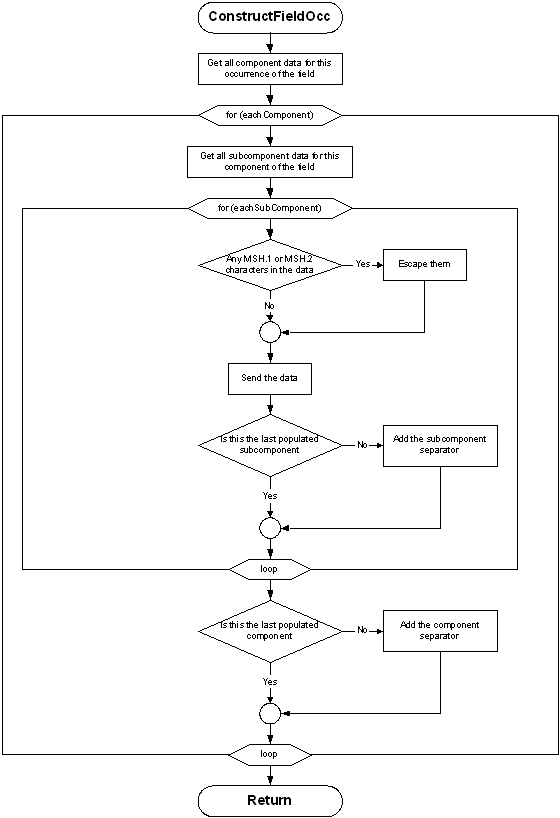
procedure construct_occurrence ( occurrence ) {
/* gather populated components */
foreach component in ( components_of( occurrence ) ) {
get_subcomponent_data( component );
/* gather all data for subcomponents */
foreach subcomponent in ( subcomponents_of( component ) ) {
/* escape the field separator */
substitute( field_separator, \F\ );
/* escape the encoding characters */
substitute( component_separator, \S\ );
substitute( repetition_separator, \R\ );
substitute( escape_character, \E\ );
substitute( subcomponent_separator, \T\ );
insert subcomponent;
if not last ( populated subcomponent ) insert subcomponent_separator; /* e.g., & */
}
if not last ( populated component ) insert component_separator; /* e.g., ^ */
}
return;
}
2.6.1.1 Message Construction Flow Chart
The flow charts on the following pages represent another view of the message construction rules. The first shows the rules for transmitting a message; the second shows transmitting field occurrences.
2.6.2 Rules for the recipient
The following rules apply to receiving HL7 messages and converting their contents to data values:
-
ignore segments, fields, components, subcomponents, and extra repetitions of a field that are present but were not expected.
-
treat optional segments that were expected but are not present as consisting entirely of fields that are not present.
-
treat fields and components that are expected but were not included in a segment as not present.
2.6.3 Encoding rules notes
If a segment is to be continued across messages, use the extended encoding rules. These rules are defined in terms of the more general message continuation protocol (see Section 2.10.2, "Continuation messages and segments").
2.7 USE OF ESCAPE SEQUENCES IN TEXT FIELDS
2.7.1 Formatting codes
When a field, component or sub-component of type TX, FT, or CF is being encoded, the escape character may be used to signal certain special characteristics of portions of the text field. The escape character is whatever display ASCII character is specified in the <escape character> component of MSH-2 Encoding Characters. For purposes of this section, the character \ will be used to represent the character so designated in a message. An escape sequence consists of the escape character followed by an escape code ID of one character, zero (0) or more data characters, and another occurrence of the escape character.
The escape sequences for field separator, component separator, subcomponent separator, repetition separator, escape character and truncation character are also valid within an ST data field.
The following escape sequences are defined: